Ray-tracing with Bounding Volume Hierarchies
When naively raytracing (with triangle primitives), for n rays and m triangles there are mn intersection tests, as every ray must check for intersection with every triangle in the scene (ignoring triangle culling).
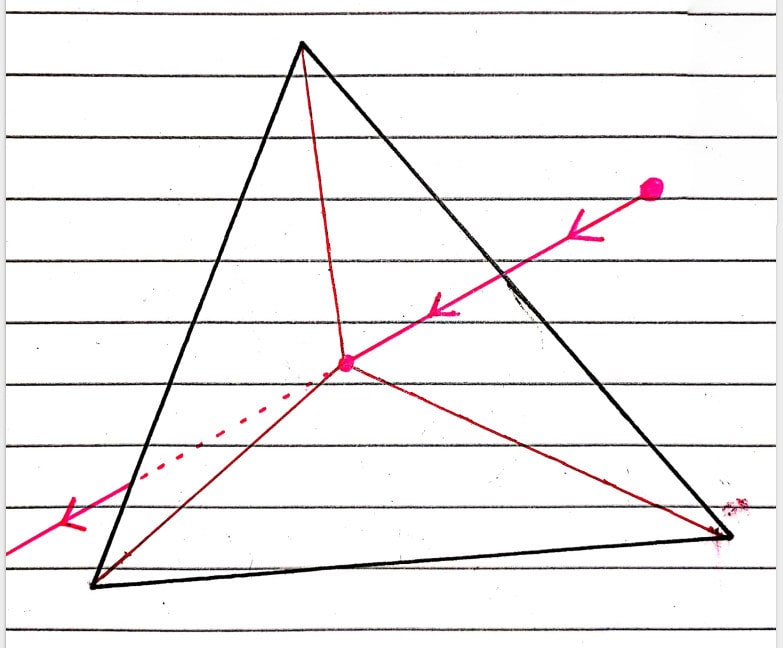
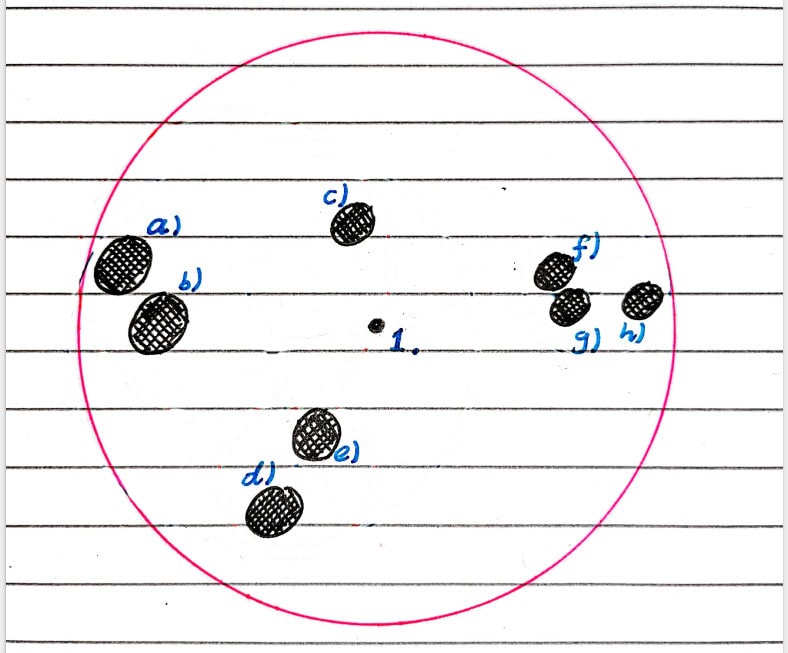
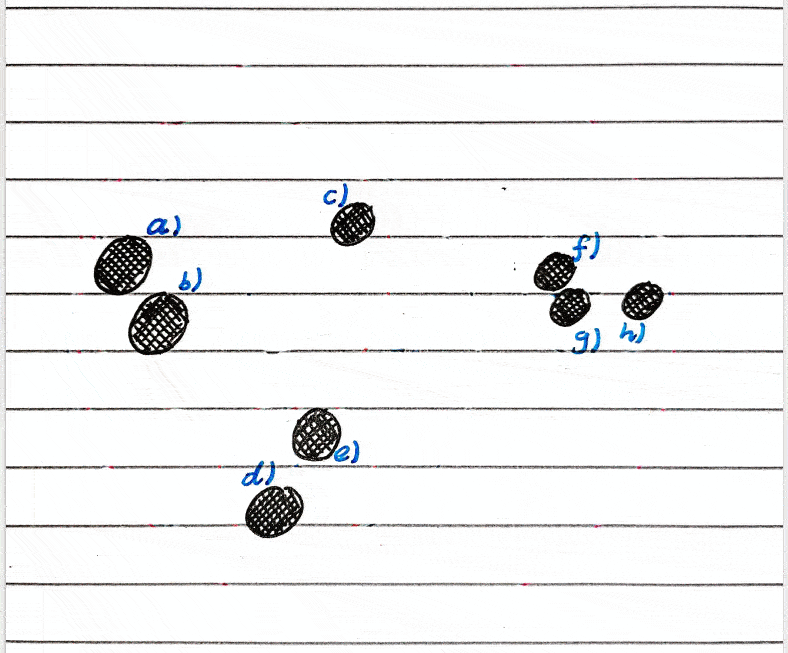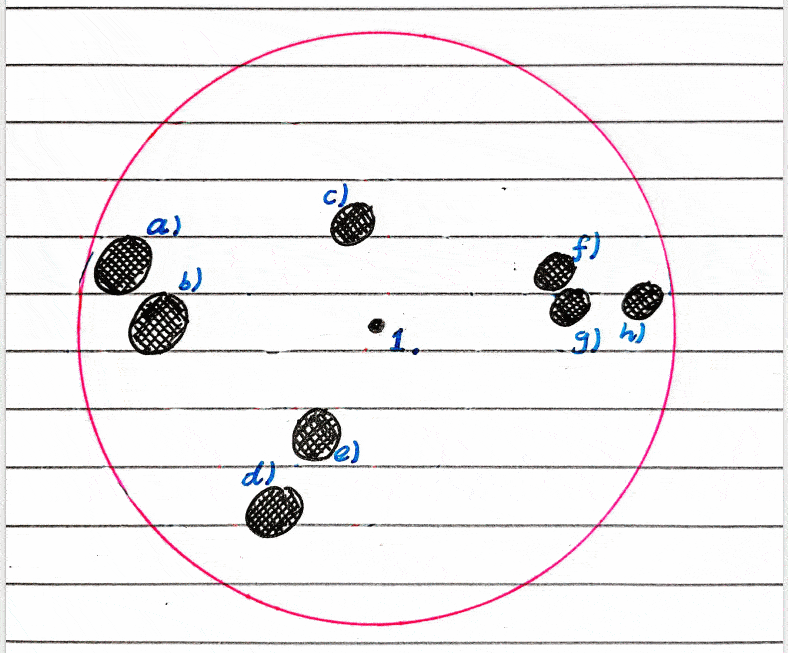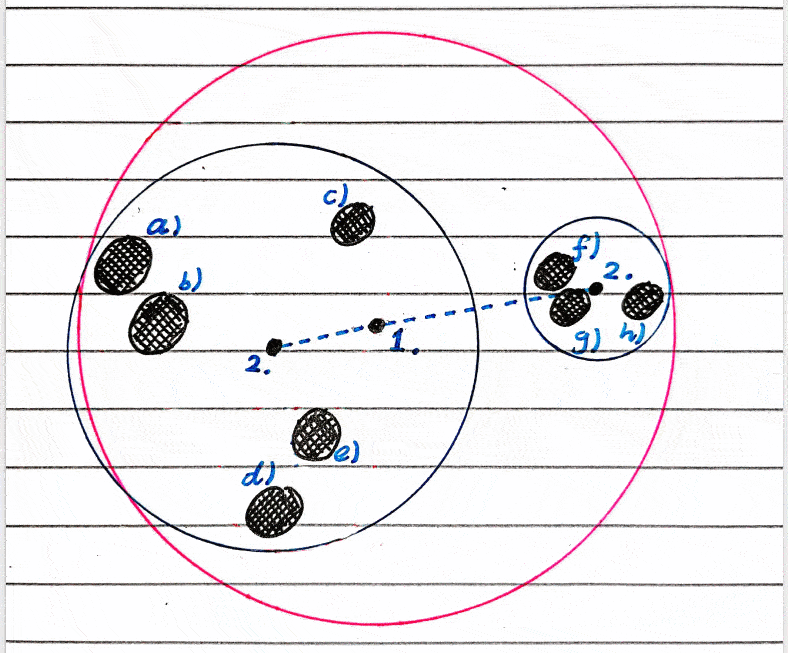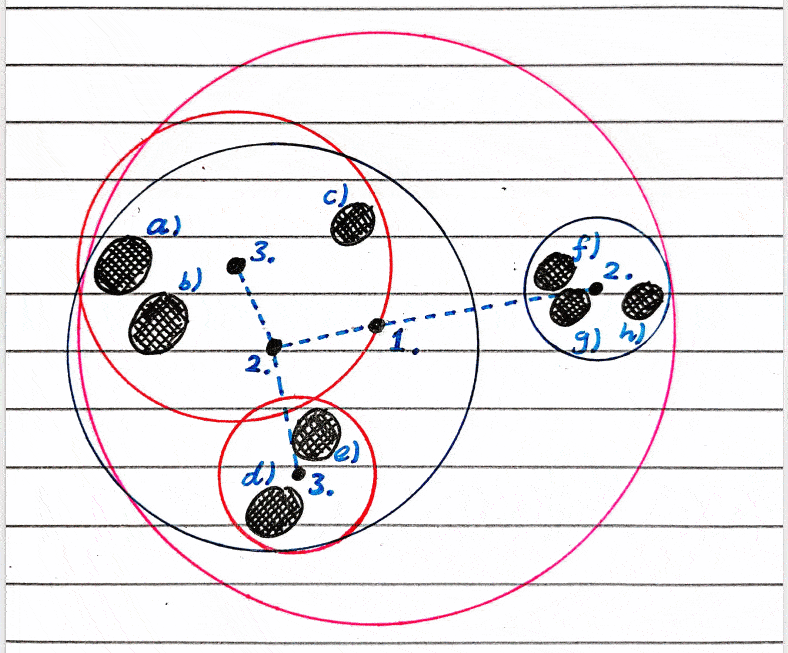
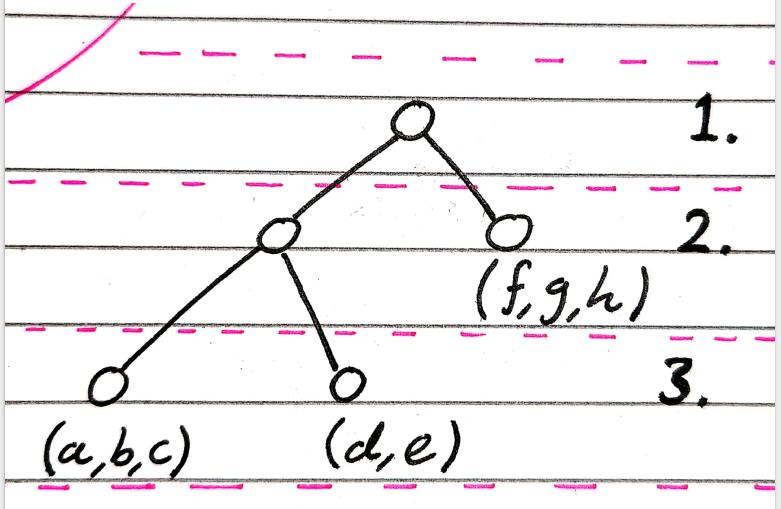
I will be making a binary tree as these are by far the most common, but there’s nothing stopping you from making a tree of higher degree.


A non-ideal case of a sphere hierarchy, and a really non-ideal case.
Constructing the BVH
I’ll be starting with a 3D model imported from a .obj file, a triangle mesh represented as an array of triangles. In my implementation I only use vertex information, no normals or UVs, as they’re unrelated to the BVH, and implementing them is it’s own task.
As we’re making a binary BVH, at every level we split the group of triangles into two groups. This splitting should be done so that each group is as spatially distinct as possible from the other. My quick and dirty solution is to calculate the variance in position of all the triangles in each dimension, relative to the centre of the BV of the group. In the process I also calculate the means position of the triangles. Then I find the dimension with the greatest variance as split along that axis, using the previously found mean position to get the mean along the splitting axis, defining the axis aligned plane that splits the triangles into two groups.
// Get the axis with the greatest variance
Axes::Axes getAxis(Vec3 variance) {
// Variance is stored in a 3-vector ordered by axis
if (variance.x > variance.y && variance.x > variance.z) return Axes::x;
else if (variance.y > variance.z) return Axes::y;
else return Axes::z;
}
// Calculate the variance of the positions of the triangle centers
// in each axis, and return the axis with the greatest variance
Axes::Axes BVHNode::calcAxisWithGreatestVariance() {
Vec3 mean, sumOfSqrs;
for (int i = 0; i < triangles.size(); i++) {
// Using Welford's method for computing variance
Vec3 center = triangles[i].getCenter();
Vec3 oldMean = mean;
mean = mean + (center - mean) / (float)(i + 1);
sumOfSqrs = sumOfSqrs + (center - mean) * (center - oldMean);
}
return getAxis(sumOfSqrs);
}
Welford’s method for computing variance.
This approach is far from ideal, and has many cases with pretty awful BV choices for the subgroups. But it works, and improvement on it is left as an exercise for the reader :).
Once we have our two subgroups, we calculate the mean position of each subgroup, and find the minimum radius of each sphere that completely covers each subgroup, by iterating over each vertex in the subgroup and calculating the distance to the mean position. Once done, we have two new BVs for our subgroups, and we can recurse downwards again!
// Partition the triangles into two groups
void BVHNode::partition(Model* model) {
std::vector<Triangle> leftPartitionTriangles;
std::vector<Triangle> rightPartitionTriangles;
Axes::Axes greatestVarianceAxis = calcAxisWithGreatestVariance();
// Partition along the axis with the greatest variance in triangle position
switch (greatestVarianceAxis) {
case Axes::x:
partitionX(leftPartitionTriangles, rightPartitionTriangles);
break;
case Axes::y:
partitionY(leftPartitionTriangles, rightPartitionTriangles);
break;
case Axes::z:
partitionZ(leftPartitionTriangles, rightPartitionTriangles);
break;
}
// Initialise the children of the node using the two separated groups
child0 = std::make_unique<BVHNode>(leftPartitionTriangles, model);
child1 = std::make_unique<BVHNode>(rightPartitionTriangles, model);
}
A major choice during the BVH construction is when to stop recursing down. We might naively keep going until we get a subgroup with a single element that can’t be split any further, but this only adds a rather unnecessary check when we should just be intersection testing against the triangle. With such small groups of triangles the benefits of a BVH can be quickly outweighed by it’s overhead.
This is a similar way of thinking to the way that the most efficient sorting algorithms are implemented, with quicksort at a high level for it’s asymptotic O(nlogn) running time, then when the sizes of the arrays to be sorted are reduced to a low enough number switching to insertion sort. Even though insertion sort has an O(n^2) running time, it can be quicker than quicksort on these small array slices due to quicksort’s overhead.
The approach I used was to just pick a minimum number of triangles that each group could have, and if a subgroup had that or below (due to splitting a group of size just above the minimum) then it wouldn’t recursively split and would instead store the triangles in it’s group.
// If the number of triangles is above the maximum, partition,
// else identify itself as a leaf node in the tree
void BVHNode::build(Model* model) {
isLeaf = true;
if (triangles.size() > maxTriangleNumPerLeaf) {
partition(model);
// Free memory
std::vector<Triangle>().swap(triangles);
triangles.clear();
isLeaf = false;
}
}
Rendering with the BVH
As stated before, we test for intersection with the BV, and if that is true then we recursively test for intersection with it’s children.
bool BVHNode::rayIntersection(const Ray& ray, float& t, int& triangleIndex) {
if (!raySphereIntersection(ray)) {
return false;
}
else if (isLeaf) {
// Test for intersection with the triangles of the leaf node
return rayTrianglesIntersection(ray, t, triangleIndex);
}
else {
// Recursively test for intersection with child nodes
return recurseRayIntersection(ray, t, triangleIndex);
}
}
The in-depth implementation of the BVH, along with a lot of extras, can be found here, along with a code repo here.
Thanks for reading, and I hope it’s been helpful! :)